CHALLENGES
Unstructured content is the dark matter of enterprise data. It exists everywhere, it contains critical information, and most data infrastructure can't touch it.
Contracts, reports, clinical notes, and records sit in formats that can't be queried, analyzed, or acted on at scale.
Teams spend hours pulling information from documents by hand, creating bottlenecks that slow every downstream process.
Patterns and signals buried across thousands of documents never surface because nobody has the bandwidth to find them.
Different people extract different things from the same document, creating data quality issues that compound over time.
Approach
We build Document Intelligence systems, designing every solution around your specific document types, extraction requirements, and downstream use cases.
01
Document type assessment and extraction architecture design
02
Model configuration, training, and validation against your actual documents
03
Integration into the workflows and systems that consume the extracted data
04
Quality assurance and governance framework for extraction accuracy over time

The output is a production system that processes documents at scale and routes extracted data to the people and systems that need it, along with the schemas, review patterns, and operational best practices.
Jacob Zweig
Managing Director, AI
Applications
Variant
Built for
Variant
Built for
Sales and revenue teams extracting insights from contracts, proposals, and customer communications
Variant
Built for
Higher Education institutions processing research documents, applications, and academic records
Variant
Built for
Healthcare organizations extracting and routing insights from clinical notes, lab reports, and patient records
Variant
Built for
Manufacturing teams processing maintenance records, inspection reports, and operational documentation
Accelerator
For organizations with critical data trapped in unstructured files, we deploy the Document Intelligence Accelerator, a Snowflake-native pipeline that turns documents into analytics-ready data.
What's included
Streams and tasks ingest documents and extract structured data via Document AI and Cortex. Handles multi-column, nested-table, and mixed content.
Defined schemas per document type, updatable as new types come online. No template rebuilding for every format.
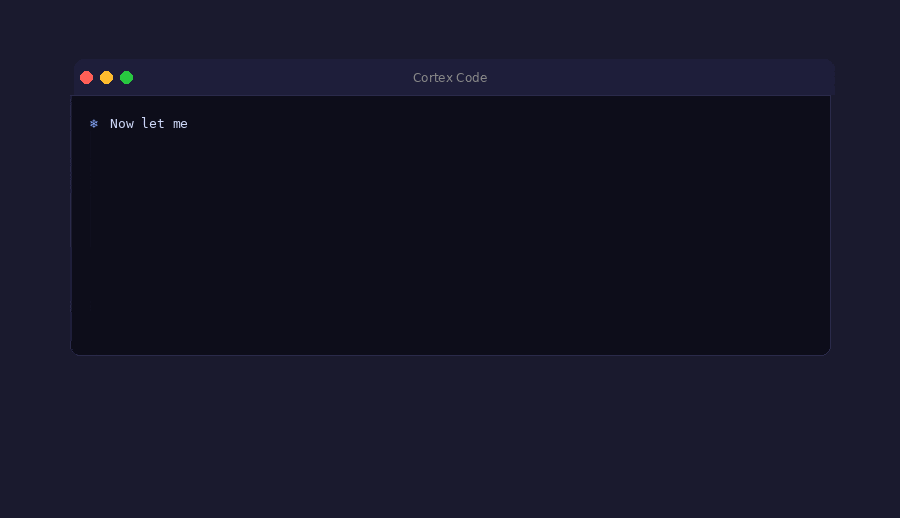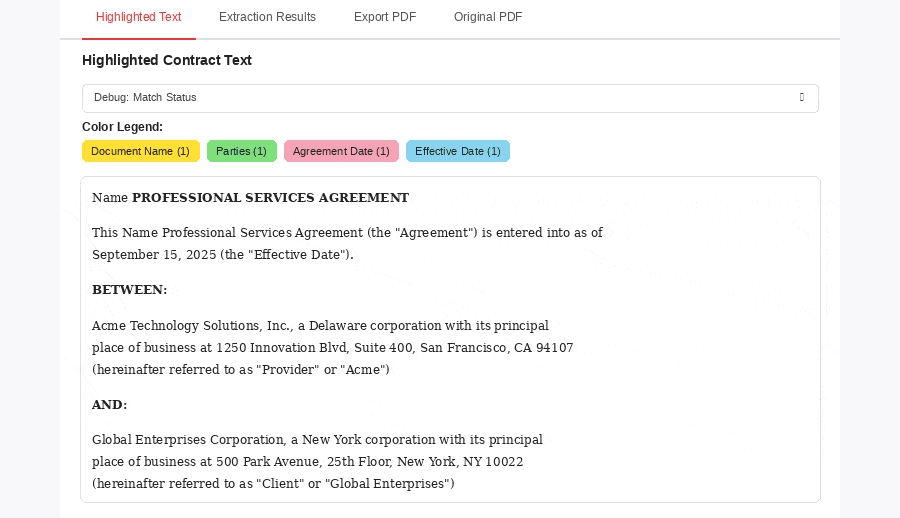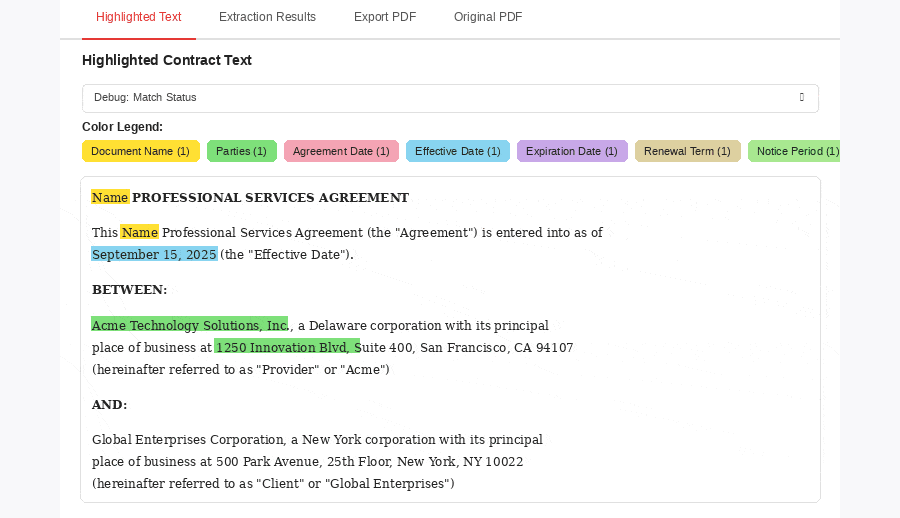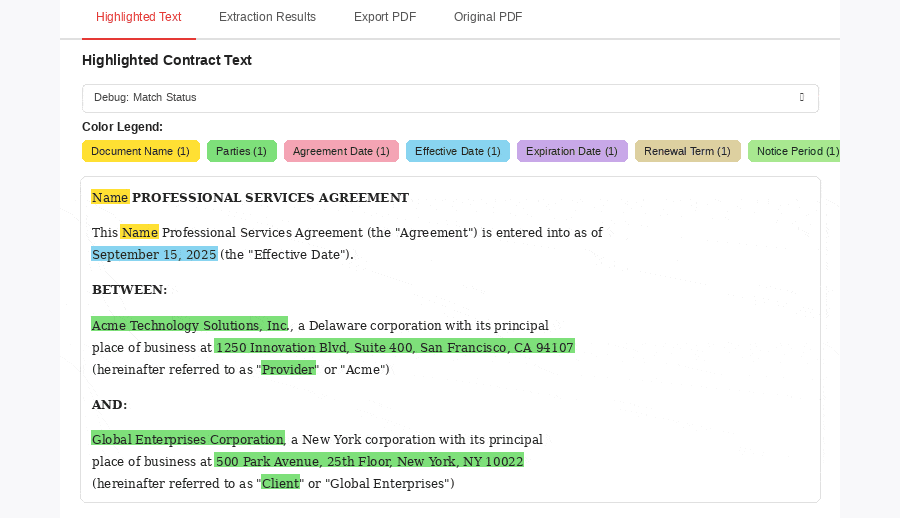
Confidence scores on every field. A Streamlit review app surfaces low-confidence extractions next to source documents, and reviewer decisions feed back as quality signal.
Output lands in governed Snowflake tables, ready for BI tools and downstream analytics. The same corpus powers semantic search, RAG, and Cortex-driven Q&A.
Process
01
Document type audit and extraction schema design
02
Pipeline setup, schema definition, and confidence threshold tuning
03
Extraction accuracy testing against representative documents
04
Production pipeline activation and review app rollout
FAQ


Contracts, clinical notes, research papers, financial reports, maintenance records, forms, invoices, regulatory filings, and more. The approach is designed around your specific document environment, not a generic template.
Accuracy depends on document type, layout consistency, and field clarity. During validation we measure performance against your actual documents and report results in terms relevant to the use case: field-level precision and recall, percentage requiring human review, and end-to-end throughput. Every extracted field carries a confidence score, so you can route high-confidence results straight to production and hold uncertain extractions for review.
Yes. Scanned and image-based documents are processed through Snowflake's Document AI and Cortex capabilities. Handwriting accuracy depends on legibility, but the same confidence scoring routes uncertain extractions to human review rather than producing silent errors.
Extracted data lands in governed Snowflake tables, immediately available to your existing BI tools, reporting layer, and downstream analytical workflows. The same parsed corpus can also power semantic search, retrieval-augmented generation, and Q&A over your document corpus.
Every extracted field carries a confidence score, and configurable thresholds determine what goes straight to production vs. what's routed to the built-in review application. Reviewers see the source document and the extracted data side-by-side, focus on the flagged fields, and approve or correct them. Their decisions feed back into the pipeline as quality signal over time.

.avif)